機械学習を利用した仮想通貨Bot作ってみた い BaseCode
はじめに
現在この記事は作成中です!
年内に完成を目指して更新していきます!
はじめまして。 jodaと申します。
今回、アイデミー様の「実践データサイエンス講座」における成果物を作成していきます。
成果物として選んだものは、
機械学習を使用した仮想通貨botとなっております。
自分はここ2年ほど、C++をベースとした
為替の自動売買システム(EA)を作って稼働させておりました。
(結果はお察しください)
心機一転、世を賑わせる仮想通貨に手を出そう!
ということで、仮想通貨botをつくっていこうと思ったのですが、
肝心のトレードロジックの検証方法がわからない状況でした。
検証方法としては、pandasを使ったり、
エクセルを使ったりいろいろな方法がある模様ですが、
どうせなら機械学習をやりたい、
ということで、アイデミー様のお世話になっている次第です。
チャレンジな内容になって来ると思いますが、
やるだけやっていこうと思います。
目次
目的
仮想通貨自動売買で、機械学習を利用し、優位性のあるロジックを発見する。
実行環境
Google Colaboratory
Python 3.7.12
crypto-data-fetcher 0.0.17
tblib 1.7.0
ディレクトリ構成
最終的に以下のようなディレクトリ構成になります。
Mydrive/
┗Colab Notebooks/
┗deliverables/
┣df_y.pkl
┣df_ohlcv.pkl
┣df_fit.pkl
┣df_features.pkl
┗deliverables.ipynb
設計
こちらの記事をベースにさせていただきまして、試行錯誤していきます。
機械学習で仮想通貨取引をするチュートリアル。python - Qiita
- 現在レートから一定距離はなれたところに指値注文を入れる。
- 特徴量としてテクニカル指標、目的変数として損益を用い、モデルを学習させる。
- 注文結果の予測が正の値である時、注文を入れるようにする。
流れ
- Google Driveのマウント
- ライブラリのインストール、インポート
- crypto-data-fetcher を利用して OHLCVを取得
- 手数料カラムを追加
- talibを用いてテクニカル分析を行い、特徴量を作成していく
- 目的変数の計算
- モデルの学習とOOS予測値計算
- バックテストと検定
- モデルの改善
- bot化して実運用
となってございます。
bot化して実運用する部分は↓の記事に記述しました。
"#$%&'(#$%&'()('&%$#$%&'()0)('&%$#"#$%&'()('&%
ここに記事のリンクを貼る
"#$%&'()0=)('&%$#"!!!#$%&'()0=~|=0)('&%$#"!#$%&
コード作成
それではコードを作成していきましょう。 最終的なコードは、githubに公開しております。 GitHub - joda-jones/deliverables
Google Driveのマウント
以下のコードを実行しないとGoogle Drive上のファイルが利用できません。
初学者の私には、こういったものが壁となりますね。
コードを実行すると、
何やら新しいタブが開きます。
ここでパスコードを要求されたり、
接続を許可するか尋ねられます。
しっかりと確認して、指示に従いましょう。
ローカル環境でジュピターNBを利用する場合は不要です。
from google.colab import drive drive.mount('/content/drive')
ライブラリのインストール
まずは必要ライブラリをインストールしていきます。
以下のライブラリをインストールしていきます。
ccxt
crypto_data_fetcher
talib
crypto_data_fetcherはrichmanbtcさんのgitからインストールさせていただきました。
talibに関してはそのままpipインストールできませんでしたので、
以下の記事を参考にさせていただきました。
Python:TA-Libでテクニカル分析、Plotlyでローソク足の描画 - Investment Tech Hack
コードは以下のようになります。
!pip install ccxt !pip install "git+https://github.com/richmanbtc/crypto_data_fetcher.git@v0.0.17#egg=crypto_data_fetcher" !curl -L http://prdownloads.sourceforge.net/ta-lib/ta-lib-0.4.0-src.tar.gz -O && tar xzvf ta-lib-0.4.0-src.tar.gz !cd ta-lib && ./configure --prefix=/usr && make && make install && cd - && pip install ta-lib
その他のライブラリに関してはすでにGoogleColaboratoryにインストールされている模様。
ライブラリのインストールが終了しましたので、
インポートしてみます。
from datetime import datetime import calendar import ccxt from crypto_data_fetcher.gmo import GmoFetcher import joblib import lightgbm as lgb import matplotlib.pyplot as plt import numba import numpy as np import pandas as pd from scipy.stats import ttest_1samp import seaborn as sns import talib from sklearn.ensemble import BaggingRegressor from sklearn.linear_model import RidgeCV from sklearn.model_selection import cross_val_score, KFold, TimeSeriesSplit sns.set()
エラーが出なければOKです。 エラーが出た場合、足りないライブラリを入れていきます。
OHLCVの取得
まずは解析するデータを取得していきます。 OHLCVとは、
一定期間(1分、5分、1時間など)の,
始値(open)、高値(high)、安値(low)、終値(close)、出来高(volume)
を表すデータです。
crypto_data_fetcherは、binance bybit ftx gmo などの
価格データ等を取得することができます。
詳細はこちら
(当初はccxtを用いて、bitgetのOHLCVを取得しておりました。
しかしながら、 ccxtは 500本までという制限があり
データ分析を行うには足りなかったのでこちらを利用させていただいています)
データは、学習用、 検証用、 テスト用の3つにわける必要があります。 この時点で、テスト用のデータを分離しておきます。
memory = joblib.Memory('/tmp/gmo_fetcher_cache', verbose=0) fetcher = GmoFetcher(memory=memory) # GMOコインのBTC/JPYレバレッジ取引 ( https://api.coin.z.com/data/trades/BTC_JPY/ )を取得 # 初回ダウンロードは時間がかかる df = fetcher.fetch_ohlcv( market='BTC_JPY', # 市場のシンボルを指定 interval_sec=15 * 60, # 足の間隔を秒単位で指定。この場合は15分足 ) # 実験に使うデータ期間を限定する df = df[df.index < pd.to_datetime('2021-04-01 00:00:00Z')] display(df) df.to_pickle('/content/drive/My Drive/Colab Notebooks/deliverables/df_ohlcv.pkl')
maker手数料カラムを追加
feeの単位には注意が必要。
%ではなく、割合表記にしないと、目的変数の計算でバグります。
詳細は、私の別記事にて。
bitgetのmaker手数料は0.04%なので、すべてが0.0004のfeeカラムを追加。
df = pd.read_pickle('/content/drive/My Drive/Colab Notebooks/deliverables/df_ohlcv.pkl') df["fee"] = 0.004 #割合表記!!!! df.to_pickle('/content/drive/My Drive/Colab Notebooks/deliverables/df_ohlcv_with_fee.pkl')
作成されたDFは以下のようになりました。
(当時の時刻からの過去データを取得するので、
セルを実行するたびにDFは更新されていきます。)

特徴量作成
テクニカル指標計算ライブラリのTA-Libを利用して特徴量を作成していきます。
talibは非常に便利で、関数一つでテクニカル指標を計算することができます。
例えば、以下のコードの
df['ADX'] = talib.ADX(high, low, close, timeperiod=14)
に着目してみます。
こちらはtalib.ADX()一つで、
dfのtimestampに対応するADXが算出できます。
引数には、高値(high)、安値(low)、終値(close)、そして算出期間を記述します。
どのテクニカル指標がモデルの予測精度を向上させるか不明ですので、
ひとまずメジャーなテクニカル指標をまとめてdfに追加することにします。
def calc_features(df): open = df['op'] high = df['hi'] low = df['lo'] close = df['cl'] volume = df['volume'] orig_columns = df.columns hilo = (df['hi'] + df['lo']) / 2 df['BBANDS_upperband'], df['BBANDS_middleband'], df['BBANDS_lowerband'] = talib.BBANDS(close, timeperiod=5, nbdevup=2, nbdevdn=2, matype=0) df['BBANDS_upperband'] -= hilo df['BBANDS_middleband'] -= hilo df['BBANDS_lowerband'] -= hilo df['DEMA'] = talib.DEMA(close, timeperiod=30) - hilo df['EMA'] = talib.EMA(close, timeperiod=30) - hilo df['HT_TRENDLINE'] = talib.HT_TRENDLINE(close) - hilo df['KAMA'] = talib.KAMA(close, timeperiod=30) - hilo df['MA'] = talib.MA(close, timeperiod=30, matype=0) - hilo df['MIDPOINT'] = talib.MIDPOINT(close, timeperiod=14) - hilo df['SMA'] = talib.SMA(close, timeperiod=30) - hilo df['T3'] = talib.T3(close, timeperiod=5, vfactor=0) - hilo df['TEMA'] = talib.TEMA(close, timeperiod=30) - hilo df['TRIMA'] = talib.TRIMA(close, timeperiod=30) - hilo df['WMA'] = talib.WMA(close, timeperiod=30) - hilo df['ADX'] = talib.ADX(high, low, close, timeperiod=14) df['ADXR'] = talib.ADXR(high, low, close, timeperiod=14) df['APO'] = talib.APO(close, fastperiod=12, slowperiod=26, matype=0) df['AROON_aroondown'], df['AROON_aroonup'] = talib.AROON(high, low, timeperiod=14) df['AROONOSC'] = talib.AROONOSC(high, low, timeperiod=14) df['BOP'] = talib.BOP(open, high, low, close) df['CCI'] = talib.CCI(high, low, close, timeperiod=14) df['DX'] = talib.DX(high, low, close, timeperiod=14) df['MACD_macd'], df['MACD_macdsignal'], df['MACD_macdhist'] = talib.MACD(close, fastperiod=12, slowperiod=26, signalperiod=9) # skip MACDEXT MACDFIX たぶん同じなので df['MFI'] = talib.MFI(high, low, close, volume, timeperiod=14) df['MINUS_DI'] = talib.MINUS_DI(high, low, close, timeperiod=14) df['MINUS_DM'] = talib.MINUS_DM(high, low, timeperiod=14) df['MOM'] = talib.MOM(close, timeperiod=10) df['PLUS_DI'] = talib.PLUS_DI(high, low, close, timeperiod=14) df['PLUS_DM'] = talib.PLUS_DM(high, low, timeperiod=14) df['RSI'] = talib.RSI(close, timeperiod=14) df['STOCH_slowk'], df['STOCH_slowd'] = talib.STOCH(high, low, close, fastk_period=5, slowk_period=3, slowk_matype=0, slowd_period=3, slowd_matype=0) df['STOCHF_fastk'], df['STOCHF_fastd'] = talib.STOCHF(high, low, close, fastk_period=5, fastd_period=3, fastd_matype=0) df['STOCHRSI_fastk'], df['STOCHRSI_fastd'] = talib.STOCHRSI(close, timeperiod=14, fastk_period=5, fastd_period=3, fastd_matype=0) df['TRIX'] = talib.TRIX(close, timeperiod=30) df['ULTOSC'] = talib.ULTOSC(high, low, close, timeperiod1=7, timeperiod2=14, timeperiod3=28) df['WILLR'] = talib.WILLR(high, low, close, timeperiod=14) df['AD'] = talib.AD(high, low, close, volume) df['ADOSC'] = talib.ADOSC(high, low, close, volume, fastperiod=3, slowperiod=10) df['OBV'] = talib.OBV(close, volume) df['ATR'] = talib.ATR(high, low, close, timeperiod=14) df['NATR'] = talib.NATR(high, low, close, timeperiod=14) df['TRANGE'] = talib.TRANGE(high, low, close) df['HT_DCPERIOD'] = talib.HT_DCPERIOD(close) df['HT_DCPHASE'] = talib.HT_DCPHASE(close) df['HT_PHASOR_inphase'], df['HT_PHASOR_quadrature'] = talib.HT_PHASOR(close) df['HT_SINE_sine'], df['HT_SINE_leadsine'] = talib.HT_SINE(close) df['HT_TRENDMODE'] = talib.HT_TRENDMODE(close) df['BETA'] = talib.BETA(high, low, timeperiod=5) df['CORREL'] = talib.CORREL(high, low, timeperiod=30) df['LINEARREG'] = talib.LINEARREG(close, timeperiod=14) - close df['LINEARREG_ANGLE'] = talib.LINEARREG_ANGLE(close, timeperiod=14) df['LINEARREG_INTERCEPT'] = talib.LINEARREG_INTERCEPT(close, timeperiod=14) - close df['LINEARREG_SLOPE'] = talib.LINEARREG_SLOPE(close, timeperiod=14) df['STDDEV'] = talib.STDDEV(close, timeperiod=5, nbdev=1) return df df = pd.read_pickle('/content/drive/My Drive/Colab Notebooks/deliverables/df_ohlcv_with_fee.pkl') df = df.dropna() df = calc_features(df) display(df) df.to_pickle('/content/drive/My Drive/Colab Notebooks/deliverables/df_features.pkl')
作成されたDFは以下のようになります。
テクニカル指標は、DF何行分かの価格データ(終値、高値,,,etc)を
利用して作られるものが多いです。
DFの上部は、テクニカル指標作成に必要な終値等の価格データの数が足りていないため、
NaNとなるものがでてきます。

どの特徴量を利用するかをコメントアウトで管理できるようにする
先程作成した特徴量をfeaturesというリストに格納し、
コメントアウトで特徴量の取捨選択ができるようになっております。
モデルはkaggleでよく用いられる「lightgbm」を利用する予定です。
回帰分析ではないので、多重共線性について考慮したほうがいいのか迷います。
例えば、
'BBANDS_upperband', 'BBANDS_middleband' 'BBANDS_lowerband'
は、以下の図のようになっております。
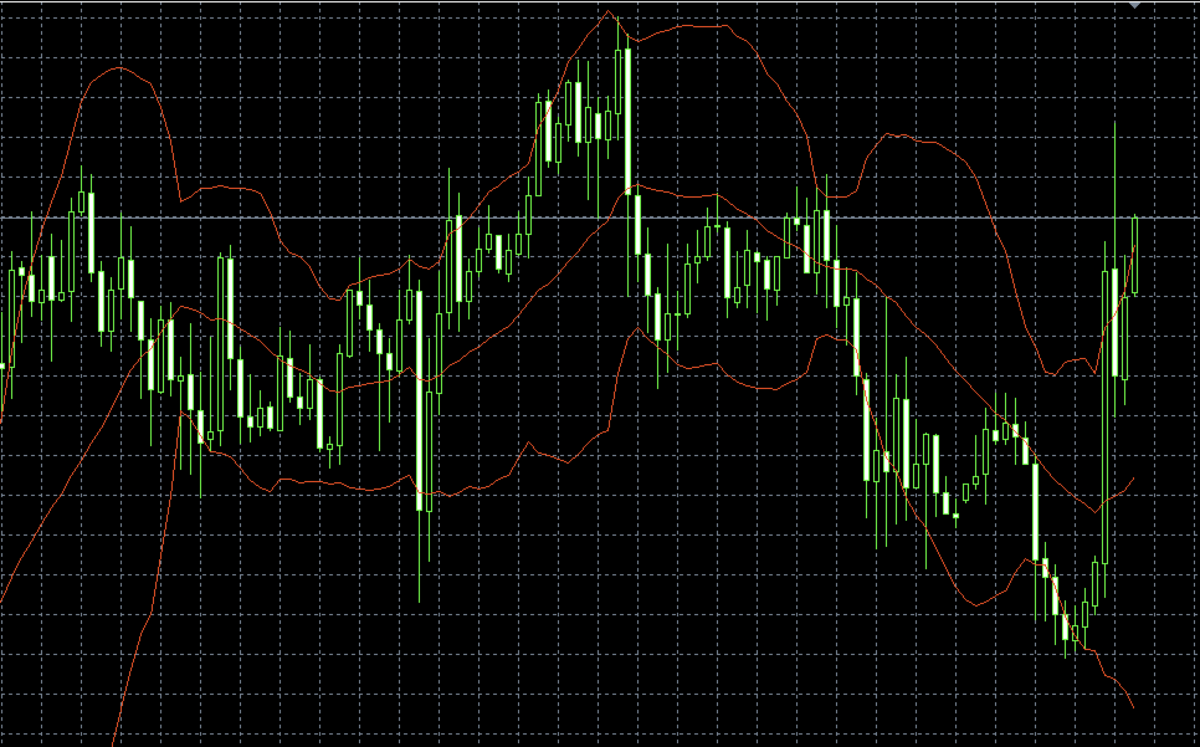
BBANDSは図の赤線3本で構成されております。
指標の内容としては単純で、
middlebandは終値の移動平均、
upperbandは、終値に、一定期間の終値の標準偏差を足したもの(上側のバンド)
lowerbandは、終値に、一定期間の終値の標準偏差を引いたもの(下側のバンド)
です。
この場合、upperbandとlowerbandは逆相関しますし、
middlebandは、他の特徴量であるEMA(指数平滑移動平均)と
順相関することが予測されます。
このような場合において、
様々な特徴量の組み合わせをスムーズに試し、
比較するために、
特徴量を簡単に選択できるようなコードを記述します。
features = sorted([ 'ADX', 'ADXR', 'APO', 'AROON_aroondown', 'AROON_aroonup', 'AROONOSC', 'CCI', 'DX', 'MACD_macd', 'MACD_macdsignal', 'MACD_macdhist', 'MFI', # 'MINUS_DI', # 'MINUS_DM', 'MOM', # 'PLUS_DI', # 'PLUS_DM', 'RSI', 'STOCH_slowk', 'STOCH_slowd', 'STOCHF_fastk', # 'STOCHRSI_fastd', 'ULTOSC', 'WILLR', # 'ADOSC', # 'NATR', 'HT_DCPERIOD', 'HT_DCPHASE', 'HT_PHASOR_inphase', 'HT_PHASOR_quadrature', 'HT_TRENDMODE', 'BETA', 'LINEARREG', 'LINEARREG_ANGLE', 'LINEARREG_INTERCEPT', 'LINEARREG_SLOPE', 'STDDEV', 'BBANDS_upperband', 'BBANDS_middleband', 'BBANDS_lowerband', 'DEMA', 'EMA', 'HT_TRENDLINE', 'KAMA', 'MA', 'MIDPOINT', 'T3', 'TEMA', 'TRIMA', 'WMA', ])
目的変数の計算
こちらに関してはかなりボリューミーになってしまいましたので、
別記事にまとめました。
ざっくりいってしまうと、
という内容です。
モデルによる学習前の結果は以下のようになりました。

図1:累積リターン
こちらは、赤線が売り、青線が買い、緑が合計のリターンを表しています。
割合で表記されています。
こちらのロジックで1BTCを売買していた場合、
15倍位にはなっていたということになりますね、、、、
matplotlibの日本語化がされていないようで、
警告が出てしまいました。
以下のように修正可能のようですが、 英語にして対応ます。
colab.research.google.com
指値を出す距離や、horizon、最大のポジション数など、
調整可能なパラメーターがあり、この辺が面白そうですが、
ひとまず学習させてどのような値になるか見てみます。
モデルの学習
LightGBMについて
それではモデルの学習をおこなっていきます。
今回利用するモデルは、 LightGBM です。
「Kaggler」の上位6割以上が LightGBM を用いている、
という集計結果もある模様です。
LightGBMについて、別記事にまとめました。
それでは学習してもらいましょう。
とりあえず、ハイパーパラメータは、random_stateを固定、
importance_type="gain"とします。
importance_typeは、特徴量重要度の形式を設定します。
Python APIのLightGBMドキュメントには、
The type of feature importance to be filled into feature_importances_. If ‘split’, result contains numbers of times the feature is used in a model. If ‘gain’, result contains total gains of splits which use the feature.
とあります。
ざっくりと申し上げますと、
‘split’ (default) → 特徴量が使われた回数
'gain' → その特徴量が使用する分岐からの目的関数の減少
となっております。
直感的に、
「何度利用されたか」、よりも、「どれくらい影響を与えたか」
のほうが、特徴量重要度としては良い気がしますね。
そのほかはデフォルトでいきます。
※LightGBMは、回帰と分類が可能ですが、デフォルトが回帰です。
これまでで作成したdfを読み込み、LightGBMのインスタンスを作成します。
df = pd.read_pickle('/content/drive/My Drive/Colab Notebooks/deliverables/df_y.pkl') df = df.dropna() model = lgb.LGBMRegressor(random_state=1)
次に、Kfold法を利用して、CVを行っていきます。
まずはdfを分割します。
cv_indicies = list(KFold().split(df))
では、dfを5分割し、リストにしてcv_indiciesに格納します。
 このような感じで、5分割したうちの1部をバリデーションデータとする、
このような感じで、5分割したうちの1部をバリデーションデータとする、
ということを5回行っています。
KFoldはデフォルトでデータを5分割する模様です。
my_cross_val_predict()では、 モデルの学習を行います。
引数、返り値は関数のdescriptionを参照ください。
簡単にいってしまうと、
- 予測された目的変数
- モデルの評価指標が入った配列
- 特徴量重要度をまとめたDF
が辞書形式ででてきます。
まず、目的変数と同じサイズのndarrayをつくります。
そして、KFold法の分割回数のforループを行い、 目的変数を予測していきます。
予測された目的変数は、
元のインデックスと対応するインデックスでy_predに格納されます。
また、各Foldの特徴量重要度をDFに格納します。
groupbyメソッドを利用して集計する必要があります。
yとy_testの散布図を取ることで、予測がうまくいっているかを確認できるようにしました。
平均2乗誤差の平方根と決定係数も出力されるようにしました。
モデルの評価をすることが可能です。
# 通常のCV cv_indicies = list(KFold().split(df)) # OOS予測値を計算 def my_cross_val_predict(estimator, X, y=None, cv=None): """ Arguments are models, features, and objective variables. Returns the predicted y, evaluation index, and feature importance as dictionary. arguments: estimator -> model X -> features(series) y -> objective variables(series) return: dictionary{"y_pred": y_pred, "evalu_array": evalu_array, "importance_df":importance_df} """ y_pred = y.copy() y_pred[:] = np.nan importance_df = pd.DataFrame({"feature":[], "importance":[]}) for train_idx, val_idx in cv: estimator.fit(X.values[train_idx], y.values[train_idx]) cols = list(X.columns)# 特徴量名のリスト f_importance = np.array(estimator.feature_importances_) # 特徴量重要度の算出 importance_df = pd.concat((importance_df, pd.DataFrame( {"feature": cols, "importance": f_importance}))) y_pred[val_idx] = estimator.predict(X.values[val_idx]) plt.plot(y, y, color = 'red', label = 'x=y') # 直線y = x (真値と予測値が同じ場合は直線状に点がプロットされる) plt.scatter(y, y_pred) # 散布図のプロット plt.xlabel('y') # x軸ラベル plt.ylabel('y_test') # y軸ラベル plt.title('y vs y_pred') # グラフタイトル plt.show() #モデルの評価 ms_error = mean_squared_error(y, y_pred) r2 = r2_score(y, y_pred) evalu_array = list([ms_error, r2]) print(f"mean squared error by oos : {ms_error}") print(f"r2_score by oos : {r2}") ret = {"y_pred": y_pred, "evalu_array": evalu_array, "importance_df":importance_df} return ret
my_cross_val_predict()を利用して、目的変数を予測していきます。
返り値を、r_buy , r_sell に格納し、分析を行っていきます。
print("prediction of y_buy") r_buy = my_cross_val_predict(model, df[features], df['y_buy'], cv=cv_indicies) print(print("prediction of y_sell")) r_sell = my_cross_val_predict(model, df[features], df['y_sell'], cv=cv_indicies)
r_buy , r_sellから特徴量重要度のDFを抽出、
groupby()メソッドにより、各Foldの特徴量重要度を平均します。
plot_feature_importance()により可視化していきます。
# 特徴量重要度を棒グラフでプロットする関数 def plot_feature_importance(df, title=None): n_features = len(df) # 特徴量数(説明変数の個数) df_plot = df.sort_values('importance') # df_importanceをプロット用に特徴量重要度を昇順ソート f_importance_plot = df_plot['importance'].values # 特徴量重要度の取得 plt.figure(figsize=(6,10)) plt.barh(range(n_features), f_importance_plot, align='center') cols_plot = df_plot['feature'].values # 特徴量の取得 plt.yticks(np.arange(n_features), cols_plot) # x軸,y軸の値の設定 plt.xlabel('Feature importance') # x軸のタイトル plt.ylabel('Feature') # y軸のタイトル plt.title(title) plt.show() #買いにおける特徴量重要度 importance_df_buy = r_buy["importance_df"] importance_df_buy = importance_df_buy.groupby("feature", as_index=False).mean().sort_values("importance", ascending=False) plot_feature_importance(importance_df_buy, "importance_buy") #売りにおける特徴量重要度 importance_df_buy = r_sell["importance_df"] importance_df_buy = importance_df_buy.groupby("feature", as_index=False).mean().sort_values("importance", ascending=False) plot_feature_importance(importance_df_buy, "importance_sell")
r_buy , r_sell から、 evalu_arrayを抽出します。
こちらはモデルの評価を量的に表すものとなっております。
こちらには、平均二乗誤差の平方根と、決定係数が格納されております。
こちらを整形してDFにし、出力します。
evalu_array = np.array([r_buy["evalu_array"], r_sell["evalu_array"]]).T evaluations_df = pd.DataFrame(evalu_array, columns = ["y_pred_buy", "y_pred_sell"], index = ["mean squared error", "r2_score"]) evaluations_df
また、df['y_pred_buy']や、df['y_pred_sell']が0より大きい時 、
リターンが得られると考えられます。
このような時のみ指値を入れた場合のシュミレーションをします。
#r_buy r_sell から y_buy と y_sellをdfに追加 df['y_pred_buy'] = r_buy["y_pred"] df["y_pred_sell"] = r_sell["y_pred"] # 予測値が無い(nan)行をドロップ df = df.dropna() print('毎時刻、y_predがプラスのときだけトレードした場合の累積リターン') df[df['y_pred_buy'] > 0]['y_buy'].cumsum().plot(label='buy') df[df['y_pred_sell'] > 0]['y_sell'].cumsum().plot(label='sell') (df['y_buy'] * (df['y_pred_buy'] > 0) + df['y_sell'] * (df['y_pred_sell'] > 0)).cumsum().plot(label='buy+sell') plt.title('Cumulative return') plt.legend(bbox_to_anchor=(1.05, 1)) plt.show() df.to_pickle('/content/drive/My Drive/Colab Notebooks/deliverables/df_fit.pkl')
ひとまずコードは以上になります。
一旦結果を見ていき、モデルの改善を行っていきます。
結果 考察
df['y_pred_buy']と、df['y_pred_sell']それぞれについて、
学習したモデルの結果を見ていきます。
モデルの評価
結論として、以下の表のようになりました。
なんと、決定係数がマイナスになっております。

表1:evaluation score
y vs y_pred_buy
赤線は、y = x
を表します。
プロットされる点が、この直線上に並ぶと、
より精度がよく予測できているということになります。
以下のようになります。
あまりうまく行っているようには見えませんね、、、
原因としては、指値が約定しない場合、目的変数は0となる
という点が大きいかと思います。
予測が大きく0に寄ってしまうのでしょう。

図1:y vs y_pred_buy
y vs y_pred_sell
y vs y_pred_buyのときと同様です。
こちらのほうが大きくマイナス、というデータが多いですね。
BTCは乱高下しながら上昇をしてきている、
ということが反映されているのかなと思います。

図2:y vs y_pred_sell
feature importanse buy
HT_DC_DCPERIODの重要度が圧倒的です。
特徴量重要度を算出できるのがLightGBMの良いところで、
特徴量の選択を容易にします。

図3:feature importanse buy
feature importanse sell
売りの際の特徴量重要度です。
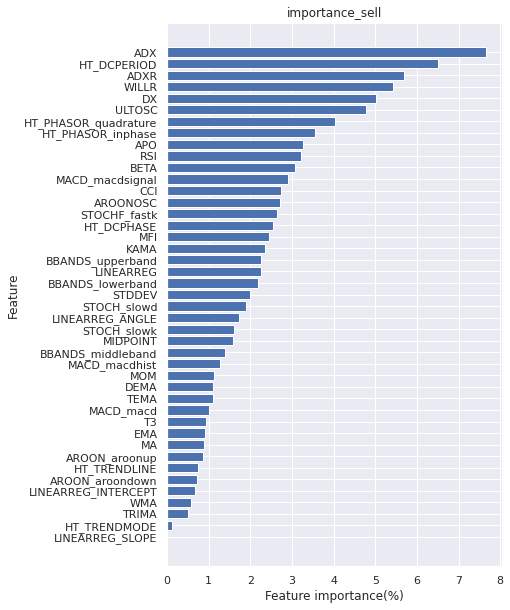
図3:feature importanse sell
累積リターン
トータルリターンは学習前と後で大差ありませんが、
DD(ドローダウン)が減っております。
50%のDDを戻すためには100%の利回りが必要です。
ですのでいかにDDを減らすことができるか、というのは
大きな課題の一つです。
予測が正のときのみトレードする、
ロジックを利用した改善はあったのではないか、
とグラフから読み取ることは可能かとおもわれます。
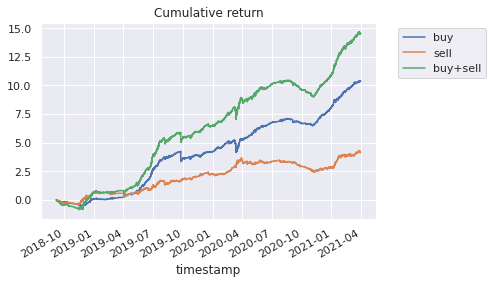
図3:cumlative return
モデルの予測精度的には正直微妙な結果となっております。 しかしながら、こちらはまだ特徴量の作成、削除、ロジック変更、 ハイパラチューニングなどを行っていません。 改良していきましょう!
当ブログは、ひとまずベースとなるコードを作成して終了いたします。
次回、改善を行った完成形コードをブログ化します。
参考
GitHub - richmanbtc/crypto_data_fetcher
機械学習で仮想通貨取引をするチュートリアル。python - Qiita
Python:TA-Libでテクニカル分析、Plotlyでローソク足の描画 - Investment Tech Hack